SOP cover visual
January 6, 2026 — AGIBOT has unveiled SOP, short for Scalable Online Post-training, a new framework designed to help robot fleets continue learning after deployment and improve their performance directly in real-world environments. The system is presented as a major step forward for physical-world VLA post-training, combining online learning, distributed architecture, and multi-task generalization in a single framework that allows robot fleets to convert scale into intelligence.
The company argues that large-scale deployment in the physical world demands more than basic task feasibility. General-purpose robots must remain stable and reliable in complex, constantly changing environments while also preserving strong generalization across very different tasks. Existing VLA pre-trained models already provide broad capability, but real-world deployment often requires higher task precision and sustained post-training to push success rates higher. AGIBOT says conventional post-training approaches remain constrained by offline data collection, single-machine learning, and sequential operation, making it difficult for robots to learn efficiently and continuously once deployed.
SOP architecture visual
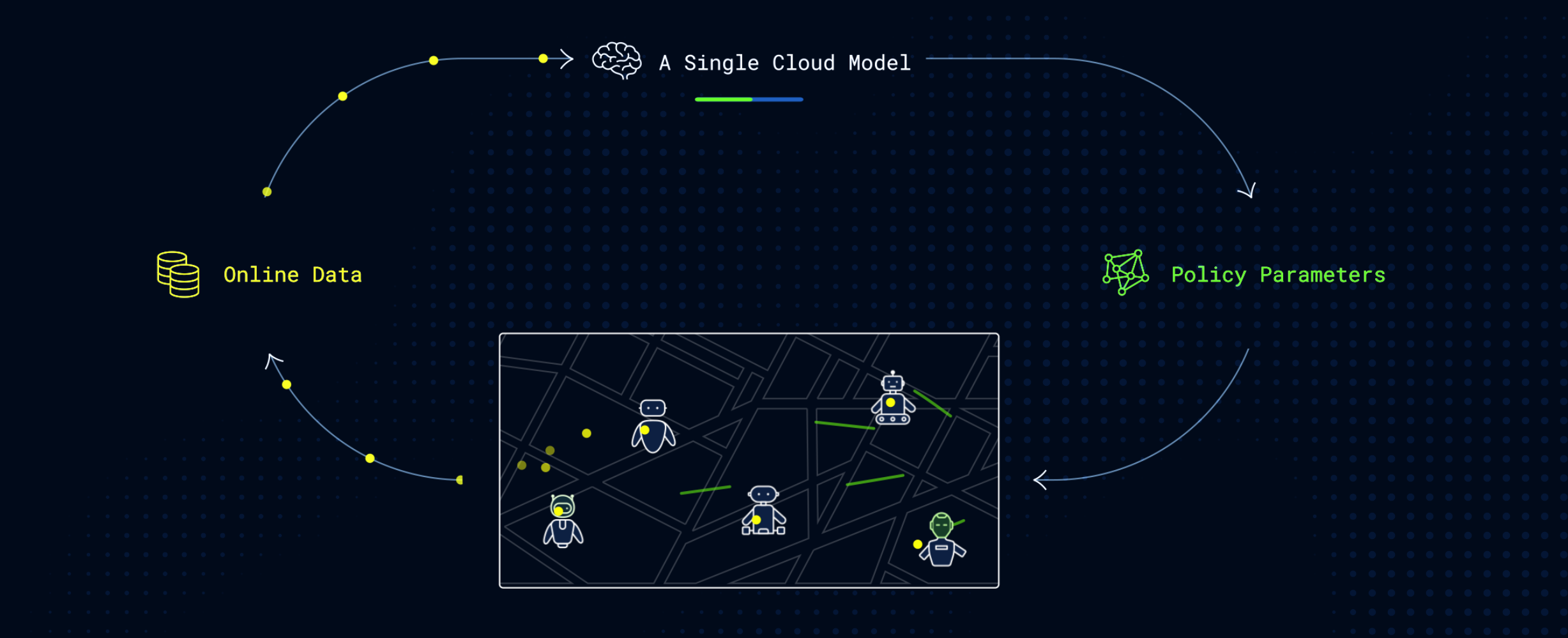
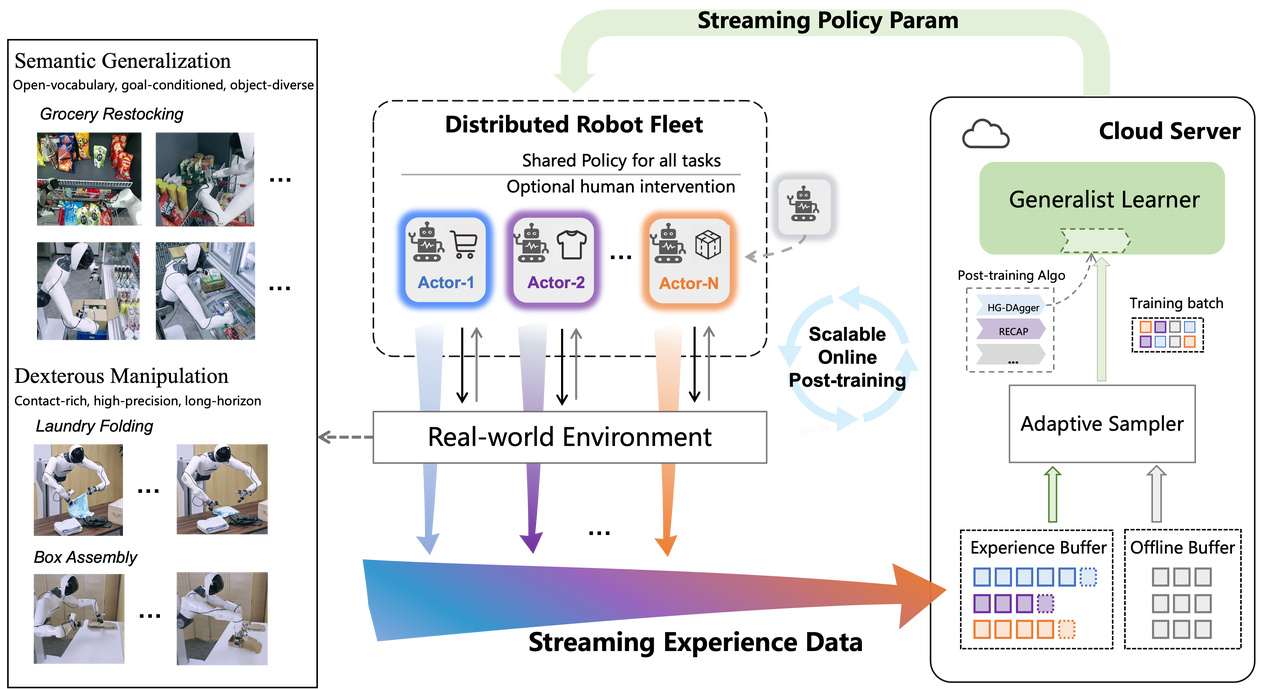
SOP is designed to change that learning paradigm. Instead of treating VLA post-training as an offline, single-machine, sequential process, AGIBOT restructures it into an online, fleet-based, parallel system. The framework runs as a low-latency closed loop in which multiple robots execute tasks simultaneously, a cloud-based learner updates the shared policy online, and newly updated model parameters are synchronized back to the robots within minutes.
At the core of SOP is an Actor-Learner asynchronous architecture. On the robot side, multiple actors running the same policy collect successful interactions, failed attempts, and human intervention data while operating across different locations and tasks. Those trajectories are uploaded in real time to a cloud learner, where online data is pooled with offline expert demonstrations. The system then uses a dynamic resampling strategy to adjust the balance between online and offline data according to task performance, allowing real-world experience to be used more efficiently.
AGIBOT says this design delivers three major advantages. First, multi-robot parallel exploration expands coverage of the state-action space far beyond what a single machine can achieve. Second, low-latency synchronization reduces distribution shift by ensuring that robots continue collecting data under the latest available policy. Third, SOP improves task performance without stripping away generalist capability. Rather than turning a VLA model into a narrow single-task expert, the framework is designed to preserve broad competence while still boosting real-world execution quality.
Performance improvement chart
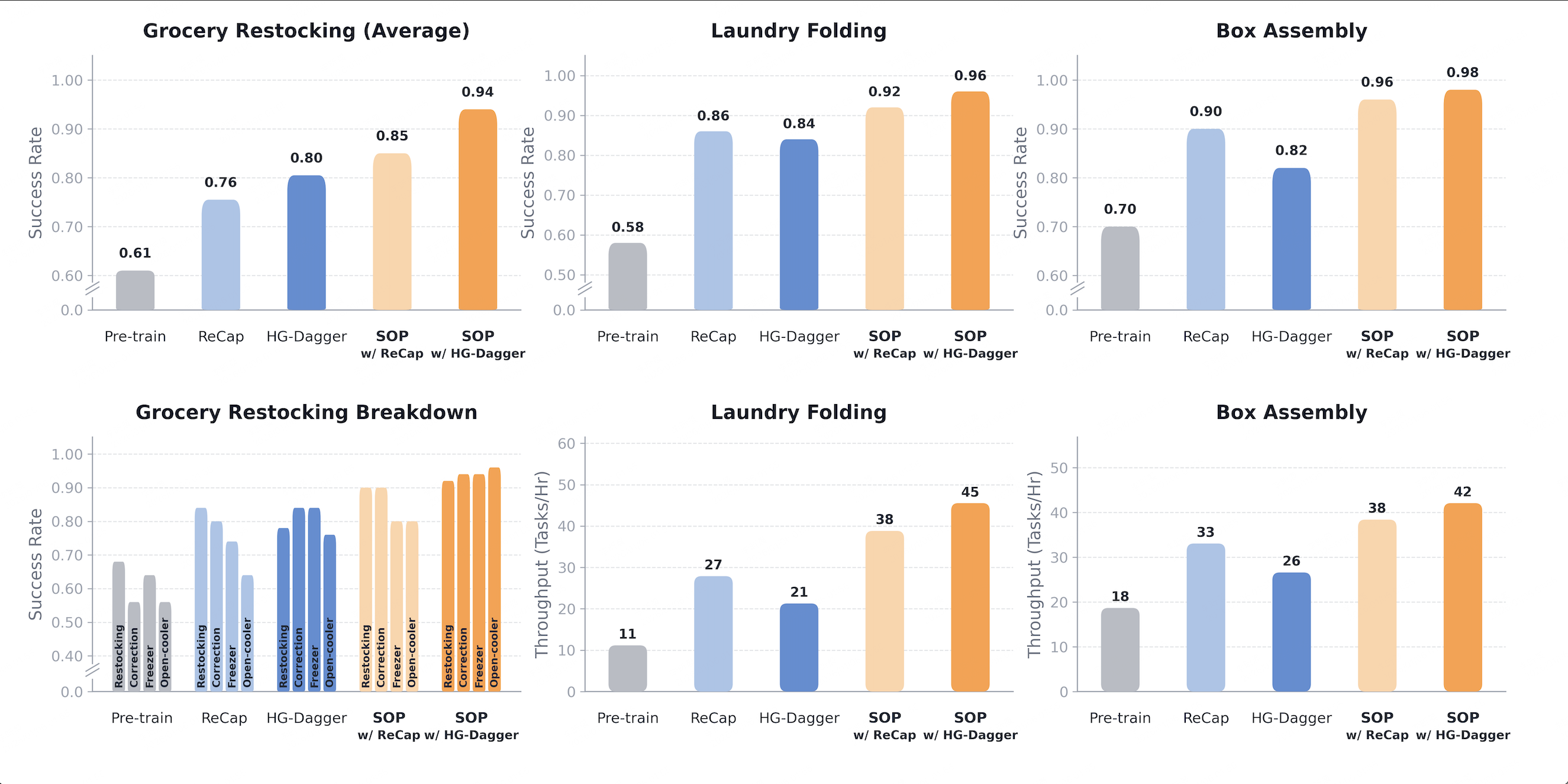
The company reported substantial experimental gains across multiple tasks. In cluttered retail environments, the SOP-enhanced HG-Dagger method delivered a 33% overall performance improvement over the pre-trained baseline. In dexterous manipulation tasks such as folding clothes and assembling paper boxes, SOP improved both success rates and throughput by enabling policies to learn from online error recovery. According to AGIBOT, success rates across multiple tasks rose above 94%, while paper-box assembly reached 98%.
AGIBOT also highlighted the effect of robot fleet size on learning efficiency. Under a three-hour training limit, a four-robot fleet achieved a final success rate of 92.5%, around 12 percentage points higher than a single-robot setup. The company said the four-robot configuration also reached target performance 2.4 times faster. In AGIBOT’s view, hardware scaling does not merely add more data collection capacity; it directly shortens the time required for real-world learning.

Learning efficiency chart
The company further explored how SOP performs across different pre-training scales. Using initial models built from 20, 80, and 160 hours of multi-task pre-training data, AGIBOT found that SOP produced stable improvements across all starting points and that final performance remained positively correlated with the quality of the pre-trained base model. At the same time, the company argued that online, on-policy experience delivers unusually strong marginal returns. In its experiments, roughly 30% performance improvement came from just three hours of on-policy experience, whereas an additional 80 hours of expert human data yielded only about 4% improvement.
The broader implication, AGIBOT said, is that deployment itself becomes part of the learning process. When robot fleets were moved into previously unseen real-world environments, both success rate and throughput dropped initially, as expected. But after only a few hours of SOP-based online training, performance rebounded sharply, allowing the robots to resume complex tasks with stronger robustness.
In AGIBOT’s framing, SOP is more than a technical update. It redefines the lifecycle of robots by turning deployment from the endpoint of development into the starting point of continuous intelligence growth. If VLA gave robots a first generation of general understanding and action capability, SOP is intended to let the shared experiences of many robots drive intelligence forward in real time.
Video References
| Segment | Duration | Link |
|---|---|---|
| SOP Intro Demo | 00:15 | Open video reference |
| 36-Hour Paper Box Folding Demo | 02:00 | Open video reference |
| 36-Hour Cloth Folding Demo | 02:39 | Open video reference |
| Stable fallback page | — | AGIBOT SOP Research Page |