Overview
Main Teaser Figure
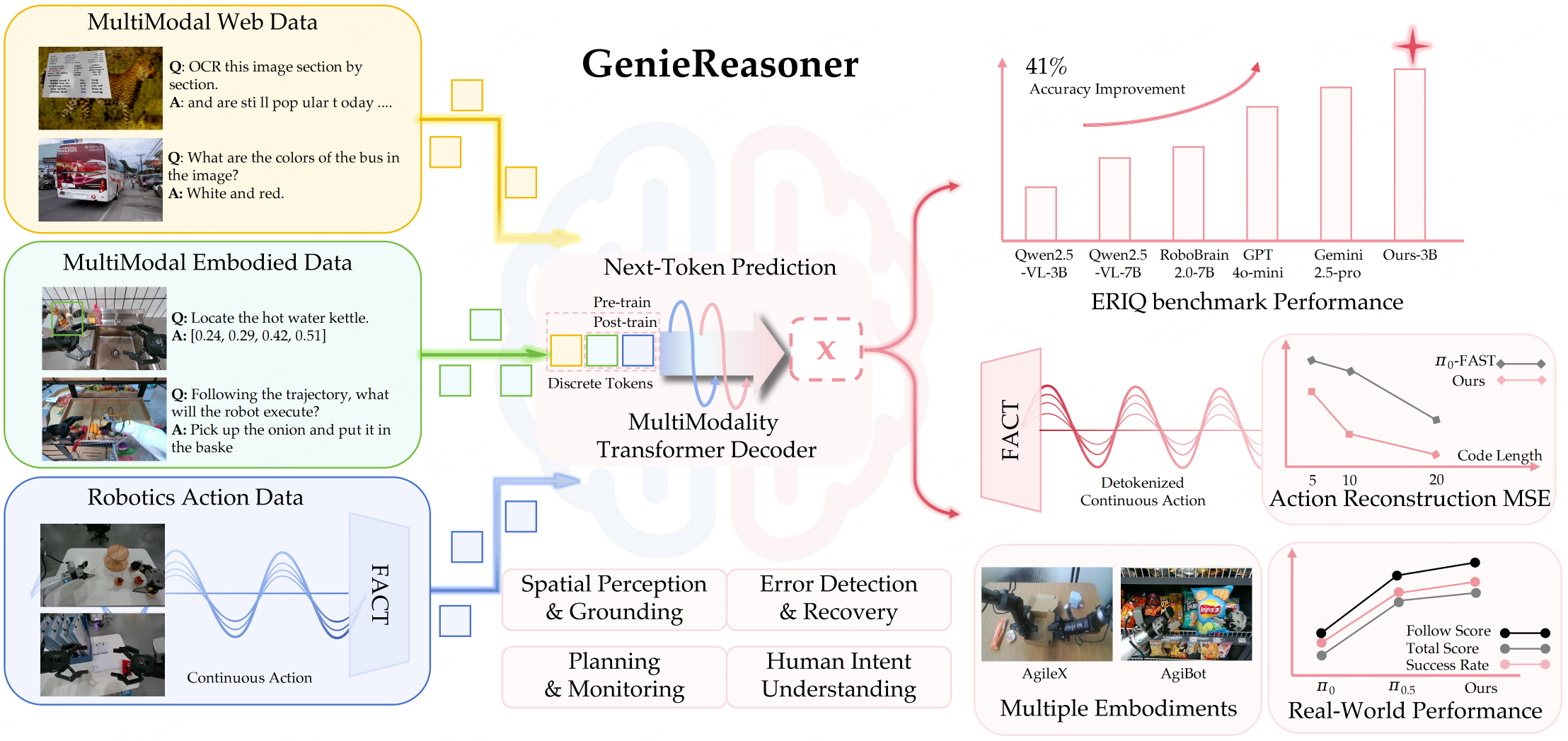
While general-purpose robots require both broad semantic reasoning and high-precision execution, existing Vision-Language-Action (VLA) models often struggle with the trade-off between these two critical capabilities. To address this, we present GenieReasoner, a unified framework that co-optimizes high-level embodied intelligence and low-level control within a single autoregressive transformer. Our work first establishes ERIQ, a comprehensive benchmark designed to quantify the reasoning bottleneck in robotic manipulation. To bridge the gap from reasoning to precise action, we introduce FACT, a novel flow-based action tokenizer that preserves high-fidelity trajectories in a discrete space. This unified design allows GenieReasoner to significantly outperform both diffusion-based and discrete-action baselines across simulated and real-world tasks.
Demos
Embodied Reasoning
-
Logic Reasoning
Identifies the target is blocked and plans a "remove-then-retrieve" action sequence.
- Open-Set Shelf Resetting
Continuously identifies and restores misplaced items, generalizing to arbitrary SKUs.
- Semantic Following
Precise semantic alignment for both single-step actions and full task execution.
- Spatial Understanding
Reasoning over geometric relationships to place objects in distinct relative orientations.
Robust Generalization
- Water Bottle
I'm thirsty, but I'm trying to lose weight. Please give me a suitable drink.
- Water Bottle (FPV)
- Red Pen
I want to write, please give me the corresponding items.
- Red Pen (FPV)
- White Wadded Paper
Pick up desktop trash.
- White Wadded Paper (FPV)
- Remote Control
I want to watch TV and switch channels. Please provide me the corresponding items.
- Remote Control (FPV)
- Charging Cable
My phone is out of battery, please give me the corresponding item.
- Charging Cable (FPV)
Human-Robot Interaction
- Cooperation
Always At Your Service
- Adversarial
Dynamic Following
- Interaction
Human Intention Understanding & Action Interaction
Methodology: GenieReasoner
Framework
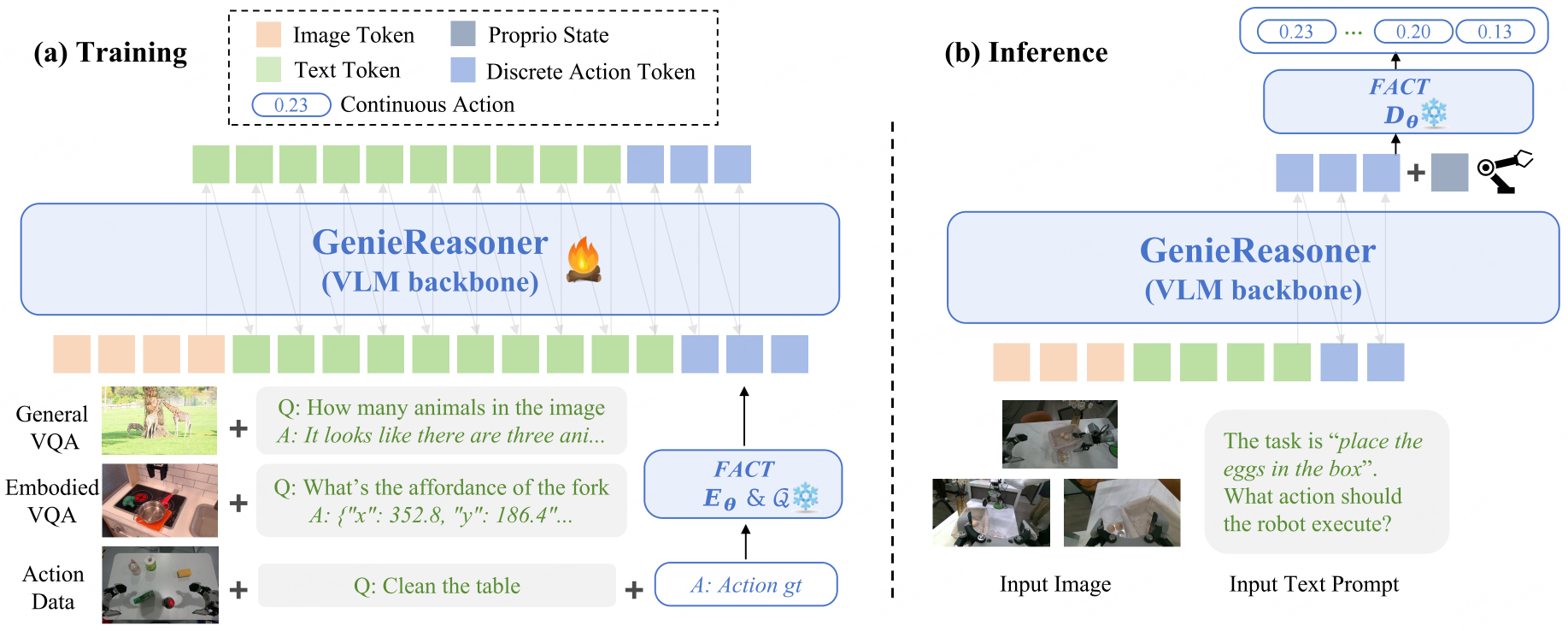
We seek a unified "Action as Language" paradigm that enables action sequences to inherit the compositional generalization of large Vision-Language Models (VLMs), while simultaneously preserving the high-precision continuous control required for reliable physical execution.
Most prior VLA systems (e.g., π0.5-style) couple a discrete VLM backbone with a continuous policy head to preserve control precision. However, the separation between token-level reasoning and continuous regression can introduce knowledge insulation, which may hinder tight reasoning-to-action alignment and lead to weaker generalization in complex, unseen scenarios.
GenieReasoner addresses this via two complementary directions:
- Unifying perception, reasoning, and action into a single discrete representation to remove cross-objective interference.
- Introducing FACT to discretize continuous trajectories with high-fidelity reconstruction.
This synergistic approach allows the entire model to be optimized with a single autoregressive objective, ensuring that abstract semantic reasoning flows seamlessly into precise physical control without compromise.
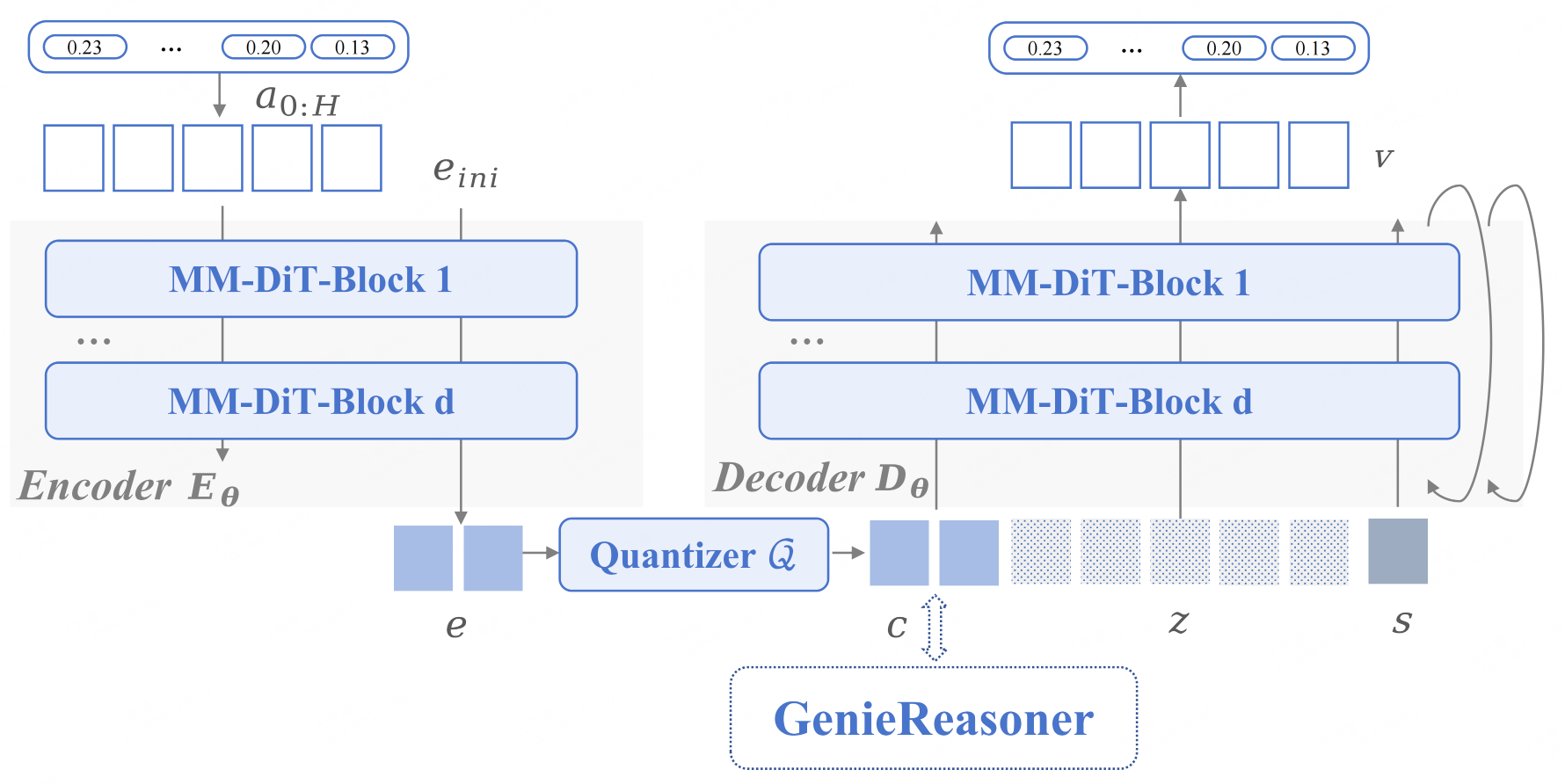
FACT: Bridging Discrete Thought & Continuous Action
FACT encodes continuous actions into discrete tokens to align with the VLM, utilizing Flow Matching to reconstruct high-fidelity trajectories from the quantized representation.
Tokenizer
Components
- VQ-Encoder
Built on the MM-DiT architecture, it compresses continuous action chunks into compact discrete tokens. This transforms complex physical dynamics into a unified vocabulary compatible with the VLM. - Flow-Matching Decoder
Leveraging an MM-DiT backbone, it utilizes Flow Matching to reconstruct high-fidelity trajectories from discrete tokens. This design ensures smooth, precise motion recovery despite the discrete bottleneck.
Why It Works Better
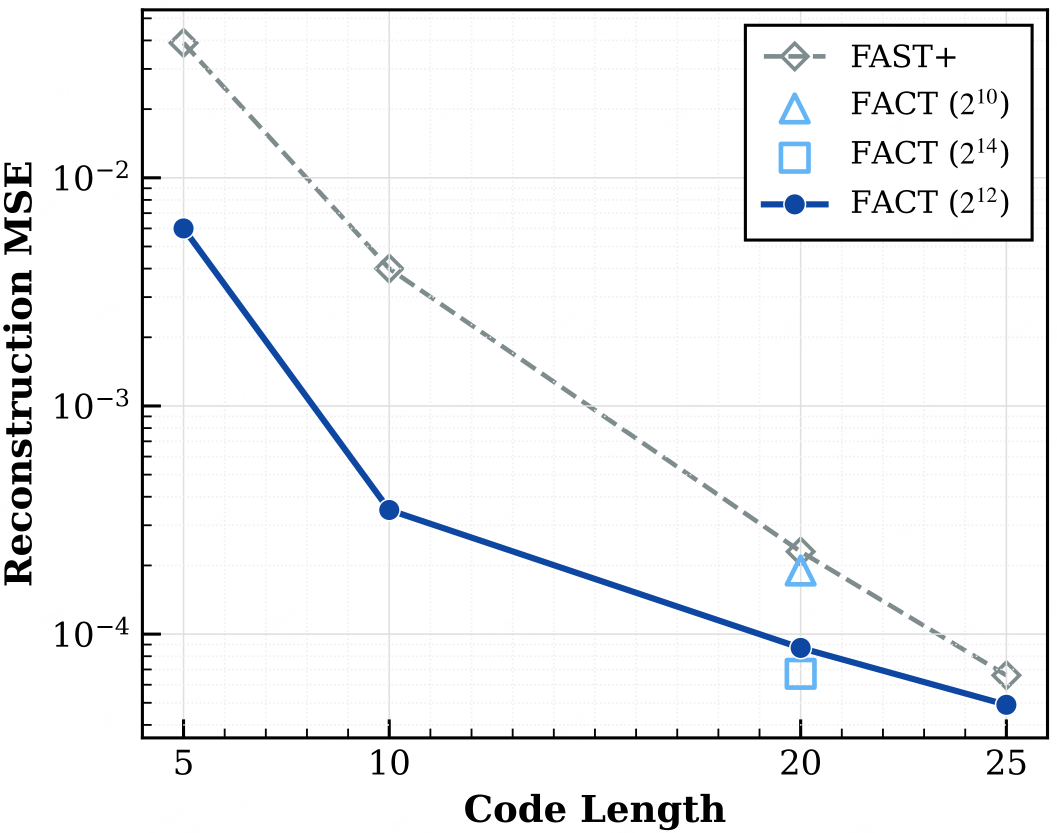
MSE Comparison
- High Fidelity
FACT achieves an order-of-magnitude lower MSE than FAST+ and significantly smaller tokens than simple binning. Its MM-DiT Flow-Matching decoder eliminates quantization artifacts, reconstructing smooth, continuous trajectories to ensure sub-millimeter precision. - Unified Space
Resolves the gradient interference that plagues hybrid architectures. By treating actions as discrete tokens, FACT aligns the motor control space with the VLM's reasoning space, allowing both to be co-optimized within a shared gradient space. - Real-World Success
By leveraging the FACT action tokenizer to bridge discrete reasoning and continuous control, GenieReasoner outperforms the discrete baseline (π0-FAST) in instruction following capabilities while surpassing continuous models (e.g., π0.5) in task success rates, ultimately achieving state-of-the-art aggregate performance.
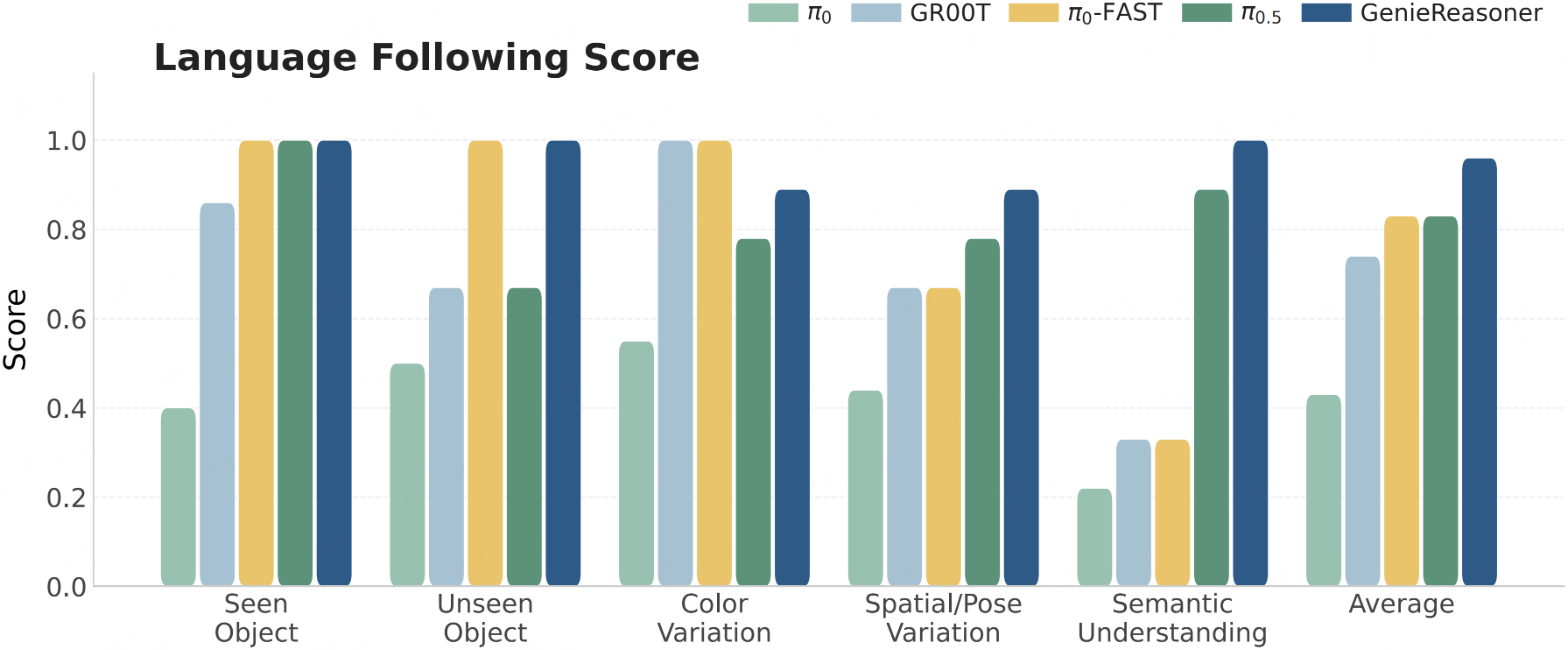
Language Following
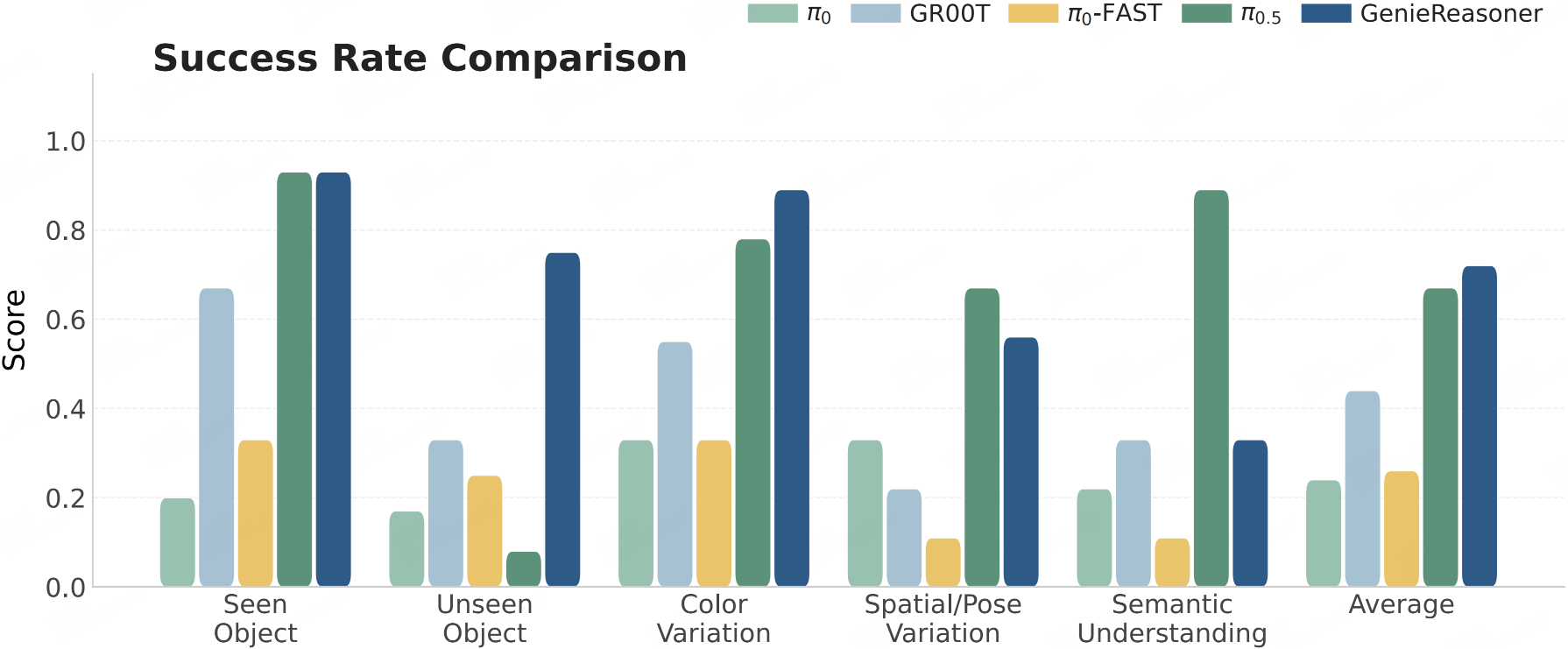
Task Success
ERIQ: A Large-Scale Benchmark for Embodied Reasoning
Design Motivation
We posit that advancing embodied reasoning is pivotal for achieving generalization and robustness in unstructured environments. Unlike traditional simulation-based VLA evaluations, ERIQ is designed to decouple and quantify task-specific reasoning capabilities, measuring the abstract cognition essential for generalization. By establishing this embodied intelligence evaluation suite, we can rigorously assess the abstract reasoning proficiency of pretrained models. This approach facilitates the optimization of multi-stage training and transforms the iterative development of VLAs into a more controllable and guided process.
Design Principles
ERIQ employs a standardized Visual Question Answering (VQA) protocol (multiple-choice or binary) to ensure deterministic, rule-based evaluation, eliminating the ambiguity of open-ended generation metrics.
The framework assesses four pillars of embodied intelligence:
- Spatial Perception and Grounding
- Error Detection and Recovery
- Planning and Monitoring
- Human-Robot Collaboration
Spanning 15 fine-grained sub-tasks and over 100 scenarios, it tests multi-modal reasoning across static, sequential, and interleaved image-text contexts.

ERIQ Benchmark Overview
Scene Distribution
- Home: 35%
- Restaurant: 20%
- Supermarket: 20%
- Industrial: 15%
- Office: 10%
Vision Source
- Static: 52.9%
- Sequential: 26.6%
- Interleaved: 20.6%
15 Diagnostic Tasks
- Scene Understanding: 967
- Success Detection: 800
- Action Understanding: 600
- Subtask Planning: 600
- Trajectory Understanding: 505
- Task Grounding: 486
- Dualview Matching: 445
- Mistake Existence: 334
- Task Progress: 281
- Relative Pos. Grounding: 249
- Human-Robot Interaction: 227
- Human Intention: 215
- Mistake Classify: 116
- Fine-grained Planning: 112
- Mistake Recovery: 105
Closing Statement
We have fully open-sourced the ERIQ Benchmark, aiming to provide a reproducible and measurable technical foundation for the embodied AI community. We sincerely invite developers and researchers to leverage this benchmark, share feedback on edge cases in real-world scenarios, and collaborate to refine the metrics for embodied reasoning, accelerating the emergence of general-purpose embodied intelligence.