Imagine bringing home a single robot as your all-in-one kitchen assistant—you want it to brew your morning Gongfu tea, make fresh juice in the afternoon, and mix the perfect cocktail at night. While it might have been trained extensively in a lab, in your house, the counter is slightly higher, the fruit varies in shape, and your cocktail shaker is transparent. Pretrained Vision-Language-Action (VLA) models provide a strong starting point, yet real-world deployment is never a fixed test distribution. This leaves a critical, unsolved challenge: how do we take the heterogeneous experience generated across a fleet of robots and use it to post-train a single generalist model across a wide range of tasks simultaneously?
We present Learning While Deploying (LWD), a fleet-scale offline-to-online RL framework for continual post-training of generalist VLA policies. Instead of treating deployment as the finish line where a policy is merely evaluated, LWD turns it into a training loop through which the policy improves. A pretrained policy is deployed across a robot fleet, and both autonomous rollouts and human interventions are aggregated into a shared replay buffer for offline and online updates. The updated policy is then redeployed, enabling continuous improvement by leveraging interaction data from the entire fleet.
A Generalist Learns Beyond Demonstrations
Some robot learning systems have explored data flywheels: deploying a policy, collecting new robot data, extracting high-quality behaviors, and training the next policy to imitate them. While this supports scalable improvement, it still treats deployment primarily as a way to collect expert demonstrations. In addition, prior post-training systems mainly focus on specialist policies, leaving open the question of how to continually improve a single generalist VLA policy across diverse tasks.
Real-world robot deployment generates a broader range of learning signals than successful trajectories alone. Successful executions, failed attempts, partial progress, failure recoveries, and human interventions can all provide useful learning signals. This is where LWD differs from existing imitation-based policy updates. Instead of filtering deployment experience into a smaller set of high-quality demonstrations, LWD learns from the entire spectrum of robot experience. The key is that LWD does not rely on imitation learning for post-training; instead, it uses offline-to-online reinforcement learning to convert heterogeneous robot experience into policy improvement.
An Offline-to-Online RL Data Flywheel
LWD drives self-improvement during real-world robot deployment through a closed-loop data flywheel. It begins with a pretrained VLA policy. The policy has broad competence from large-scale robot data, but it is not assumed to be deployment-ready. LWD first performs offline RL initialization using previously collected robot data, including expert demonstrations, historical rollouts, and exploratory data around failure modes. This gives the policy and critic a stable starting point before online deployment.
Then the online stage begins. The current policy is deployed across a fleet of robots. Each robot executes real-world tasks and uploads trajectories into a shared online replay buffer. Some trajectories succeed. Some fail. Some include human interventions. The centralized learner trains on a mixture of the static offline buffer and the growing online buffer, then periodically pushes the updated policy back to the fleet.
This creates a closed-loop RL data flywheel:
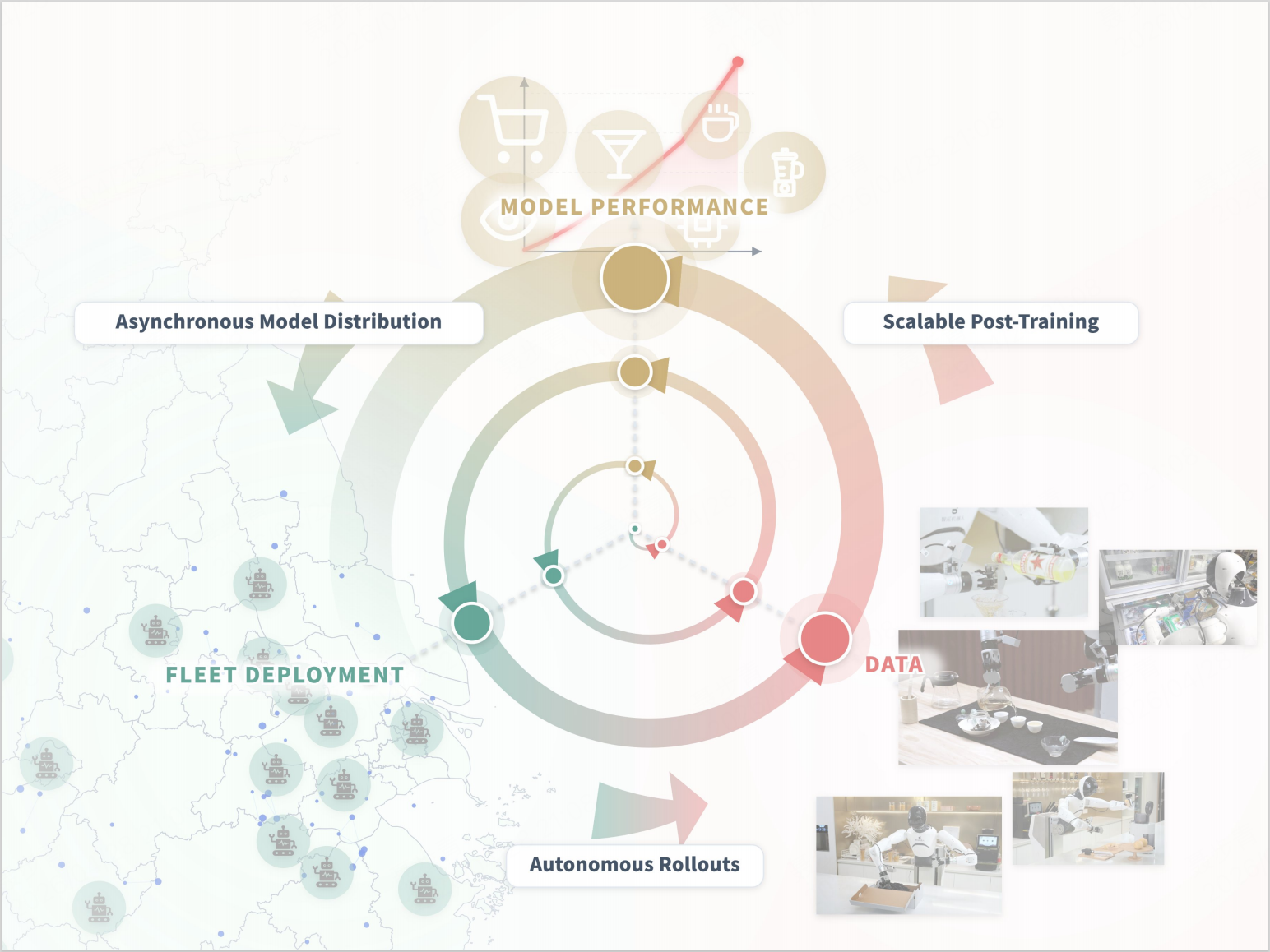
LWD-based data flywheel
The important distinction is that LWD uses a unified reinforcement learning method across offline and online stages. The offline stage provides a stable foundation, while the policy is exposed to the real-world deployment distribution during the online stage. Data from both training stages is used by the same learner to improve a single generalist policy, leading to more stable training. In this sense, LWD is more than a deployment data flywheel. It is a unified offline-to-online RL flywheel for continual policy improvement.
Challenges of Fleet-Scale RL for Generalist Policies
Learning from deployment sounds natural, but applying RL to a generalist robot fleet is difficult. Fleet replay is highly heterogeneous, mixing tasks with different instructions, horizons, reward sparsity, success frequencies, and degrees of human intervention. Stable value learning is required to extract useful improvement signals from sparse and delayed rewards without overfitting to transient online data. Moreover, modern VLA policies often use generative action heads such as flow-matching. These policies generate actions through a multi-step denoising process, making likelihood-based policy extraction or direct policy-gradient training difficult to apply.
LWD addresses these challenges with two components: Distributional Implicit Value Learning (DIVL) for value learning, and Q-learning with Adjoint Matching (QAM) for policy extraction.
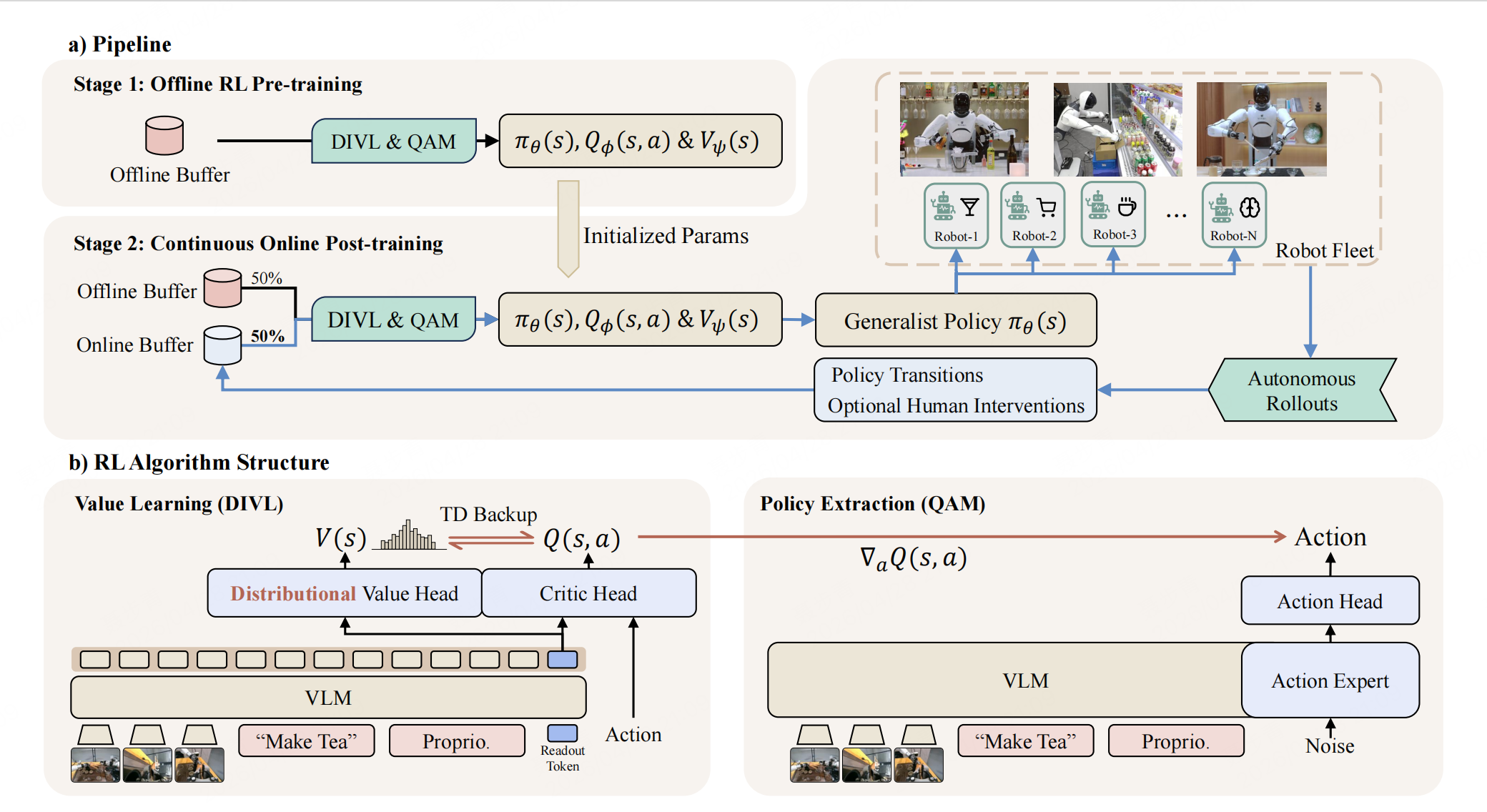
Algorithm structure of LWD
Distributional Implicit Value Learning
To learn from deployment experience, the system must decide which actions contributed to success, which led to failure, and how early decisions affected outcomes much later. This is crucial for long-horizon tasks such as brewing Gongfu tea, where a late-stage failure may originate from an earlier poor grasp or unstable placement.
In LWD, this problem is further complicated by the continually changing mixture of demonstrations, historical rollouts, online attempts, interventions, successes, and failures. Given sparse rewards, delayed feedback, and shifting data distributions, directly fitting scalar value targets becomes unstable and difficult to scale.
LWD addresses this with Distributional Implicit Value Learning (DIVL). Instead of regressing a single scalar value, DIVL learns a distribution over action values in the dataset and extracts a quantile statistic as the temporal-difference bootstrap target. This preserves the in-distribution value-learning principle of IQL, while capturing variability across heterogeneous replay and reducing overestimation from out-of-distribution maximization. For long-horizon tasks, LWD further uses multi-step TD targets to propagate sparse terminal rewards more efficiently through long episodes.
Policy Extraction with QAM
A flow-based policy generates actions through a multi-step generative process. Classic RL algorithms struggle in this setting: action likelihoods are hard to compute, and direct critic-gradient optimization requires unstable multi-step backpropagation through the flow process.
To address this challenge, LWD utilizes Q-learning with Adjoint Matching (QAM) for policy extraction. QAM uses the critic gradient to guide policy extraction for flow-based action models. It reformulates critic-guided optimization as local regression along the flow trajectory, avoiding unstable backpropagation through the full generative process and removing the need for tractable action likelihoods.
Overall, DIVL and QAM decouple policy evaluation from policy extraction: DIVL learns value estimates from heterogeneous offline and online replay, while QAM converts these estimates into stable updates for the flow-based policy.
Generalist Policy for Multiple Real-World Tasks
We evaluate LWD on a fleet of Agibot G1 dual-arm robots across eight real-world manipulation tasks, including several long-horizon tasks that last 3-5 minutes, as well as grocery restocking. All experiment videos are shown at 1x speed.
-
Fleet of Robots
-
Brew Gongfu Tea
-
Make Cocktail
-
Make Fruit Juice
-
Pack Shoes
-
Grocery
These tasks are substantially more challenging than short-horizon manipulation. Each episode lasts several minutes and requires a sequence of tightly coupled subtasks: measuring and mixing ingredients, pouring liquids, cutting and transferring fruit, manipulating containers, operating tools, packing deformable objects, and recovering from intermediate mistakes. A small error early in the episode can affect success much later, making credit assignment especially difficult.
LWD trains a single generalist policy across all tasks rather than one specialist controller per task. As online fleet experience accumulates, the policy improves more clearly on these long-horizon tasks, where deployment naturally produces the kinds of data imitation learning struggles to use: failed attempts, partial progress, retries, recoveries, and human interventions.
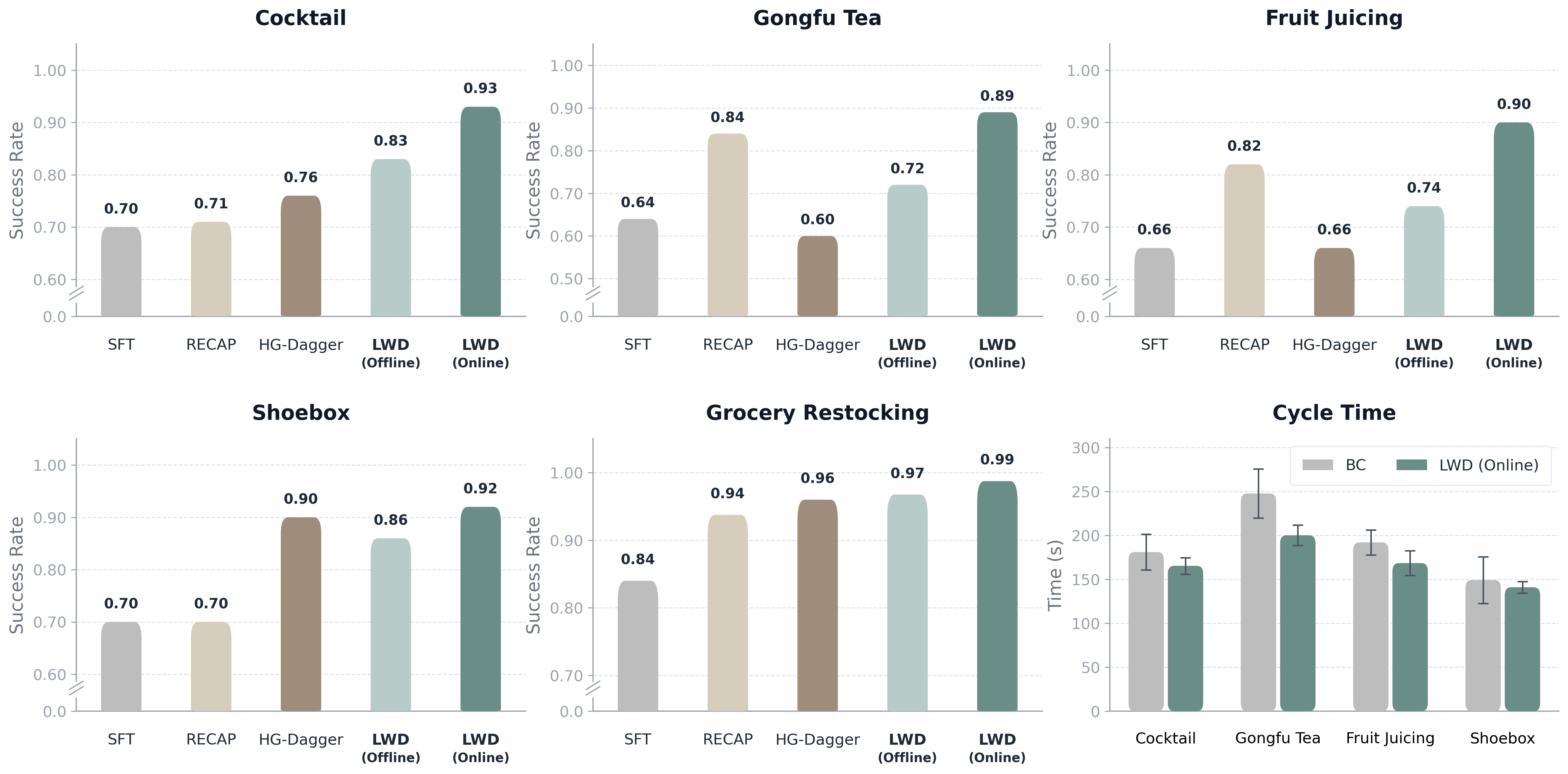
Experiment results on success rate and cycle time
The results show that LWD consistently improves the success rate over prior post-training baselines, especially for long-horizon tasks. In addition, LWD reduces mean cycle time on long-horizon tasks. This indicates that LWD improves solution quality and efficiency through offline-to-online post-training.
Toward Large-Scale Deployment
More broadly, LWD points toward a new paradigm for training generalist robot policies at deployment scale. As robot fleets scale to more homes, stores, factories, and everyday environments, deployment will generate a new kind of training data: large-scale, heterogeneous, and grounded in real-world interaction. Such experience is difficult to pre-collect in a fixed offline dataset, but it naturally emerges when robots operate at scale.
In the future, large-scale deployment could become part of the training pipeline for generalist robot policies. Offline pretraining provides the foundation, while continual offline-to-online learning turns real-world fleet experience into policy improvements. LWD represents a step toward this future: training generalist robots not only from human demonstrations, but from the full spectrum of real-world experience accumulated across robot fleets.