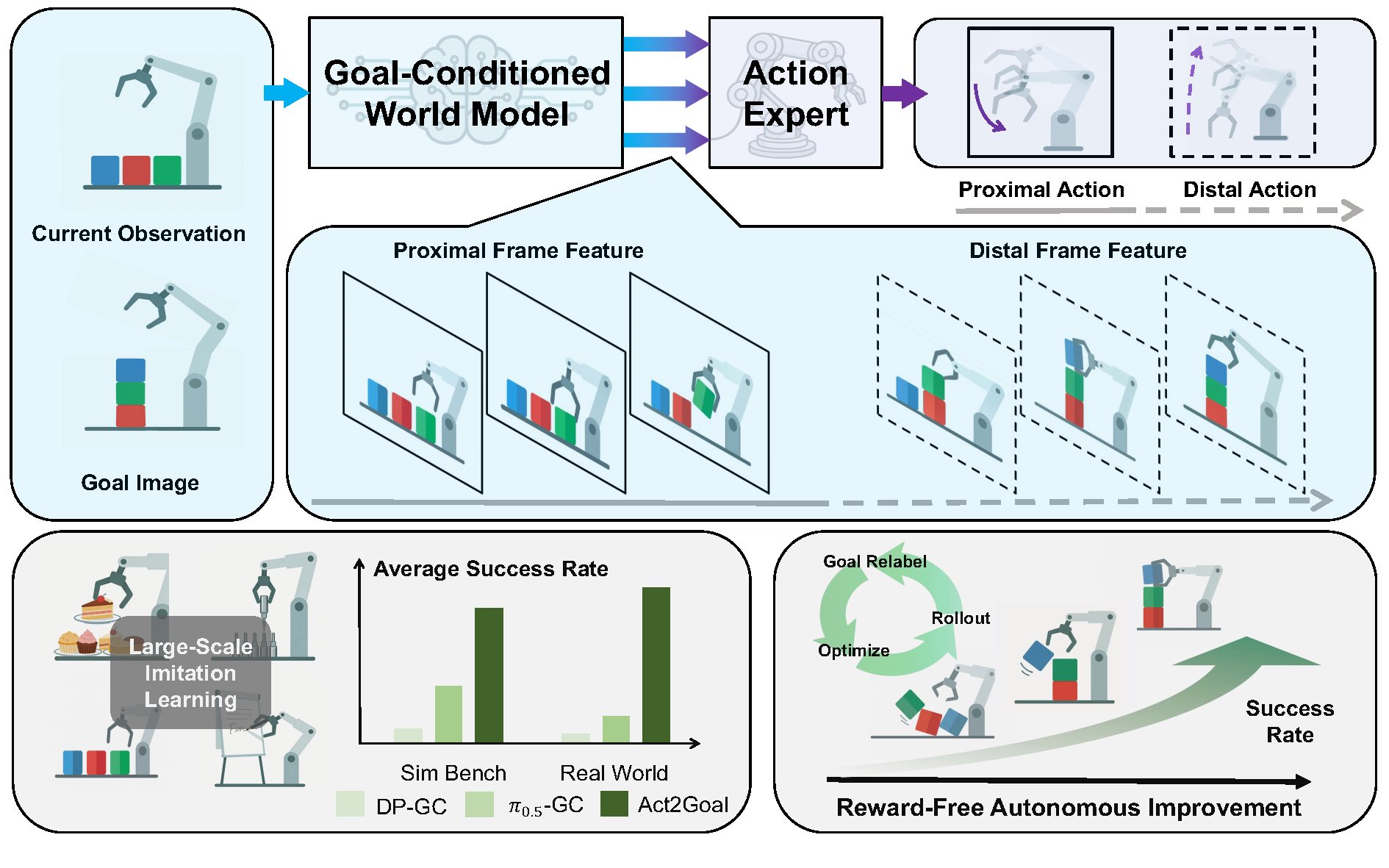
System overview of Act2Goal
Generalization
Real-world scenarios that are difficult to specify precisely via language and require fine-grained control for successful execution.
In-Domain
-
Write
The robot writes the English word shown in the goal image on a whiteboard using a marker pen.
-
Dessert
The robot performs dessert plating with reference to a given goal image.
-
Plug-In
Following the goal image's guidance, the robot picks up bearing workpieces and inserts them into small holes one by one.
Out of Domain
-
Write
The robot writes words unseen during training on a whiteboard using a marker pen.
-
Dessert
The robot performs dessert plating with reference to a given goal image, using a plate and dessert types unseen in the training data.
-
Plug-In
The robot completes a plug-in task unseen in training: inserting a cylindrical drink bottle into a cup holder.
Real-World Tasks Results
| Model/Task | Whiteboard Word Writing | Dessert Plating | Plug-In Operation | |
|---|---|---|---|---|
| ID | DP-GC | 0.00 | 0.10 | 0.00 |
| π0.5-GC | 0.23 | 0.18 | 0.00 | |
| HyperGoalNet | 0.00 | 0.08 | 0.00 | |
| Act2Goal | 0.93 | 0.75 | 0.45 | |
| OOD | DP-GC | 0.00 | 0.00 | 0.00 |
| π0.5-GC | 0.20 | 0.05 | 0.00 | |
| HyperGoalNet | 0.00 | 0.00 | 0.00 | |
| Act2Goal | 0.90 | 0.48 | 0.30 |
Simulated Benchmarks
Four tasks from the RoboTwin 2.0 benchmark with both easy (no noise) and hard (with noise) environment settings.
| Model/Task | Move Can | Pick Bottles | Place Cup | Place Shoe | |
|---|---|---|---|---|---|
| Easy | DP-GC | 0.18 | 0.04 | 0.03 | 0.04 |
| π0.5-GC | 0.54 | 0.13 | 0.16 | 0.30 | |
| HyperGoalNet | 0.11 | 0.08 | 0.08 | 0.01 | |
| Act2Goal | 0.62 | 0.80 | 0.64 | 0.52 | |
| Hard | DP-GC | 0.00 | 0.00 | 0.00 | 0.00 |
| π0.5-GC | 0.42 | 0.06 | 0.04 | 0.06 | |
| HyperGoalNet | 0.00 | 0.00 | 0.00 | 0.00 | |
| Act2Goal | 0.13 | 0.43 | 0.13 | 0.15 |
Autonomous Improvement
Rapid improvement of success rate by Online-training.
Real-World Examples
-
Drawing Unseen Pattern 1
The robot learns to draw a cross (unseen pattern in training) through 27-min of online training.
-
Drawing Unseen Pattern 2
The robot learns to draw a paper clip (unseen pattern in training) through 20-min of online training.
-
Plug bottle into cup holder
The robot learns to accurately place beverages into cup holders through 17-min of online training.
Simulated Benchmarks
Online-training effectiveness test in the Robotwin Simulator.
Figure on the left shows success rates improvement for all four challenging scenarios.
Figure in the middle shows success rates improvement for different replay buffer settings.
Video on the right demonstrates the progress of the robot's movements during online simulation learning.
(A: Move Can Pot, B: Pick Bottles, C: Place Cup, D: Place Shoe)
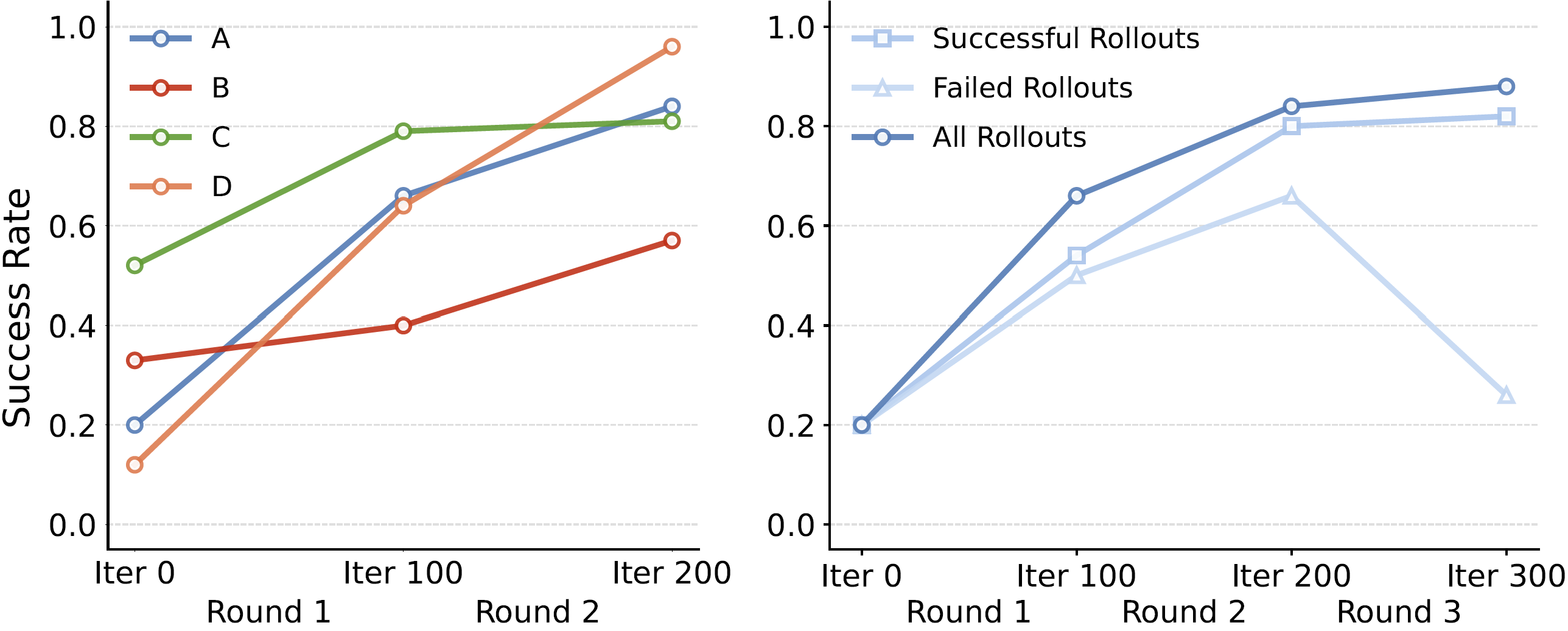
Online training results comparison
Ablation Study for Multi-Scale Temporal Hashing
The MSTH-based prediction strategy significantly outperforms the widely-used fixed-horizon action chunking approach in goal-conditioned tasks, particularly for long-horizon scenarios.
| Model | Short | Medium | Long | |
|---|---|---|---|---|
| ID | w/o MSTH | 0.95 | 0.35 | 0.10 |
| w/ MSTH | 0.95 | 0.90 | 0.90 | |
| OOD | w/o MSTH | 0.60 | 0.20 | 0.00 |
| w/ MSTH | 0.93 | 0.90 | 0.88 |
Goal-conditioned Video generation via MSTH
The video is divided into two parts: a short-horizon proximal segment with densely and uniformly sampled future states for fine-grained dynamics, and a long-horizon distal segment with logarithmically spaced samples from the remaining path to the goal, enabling coarser, goal-directed planning.